Our paper is available here.
Our project is available at https://github.com/InstallB/video_distillation.
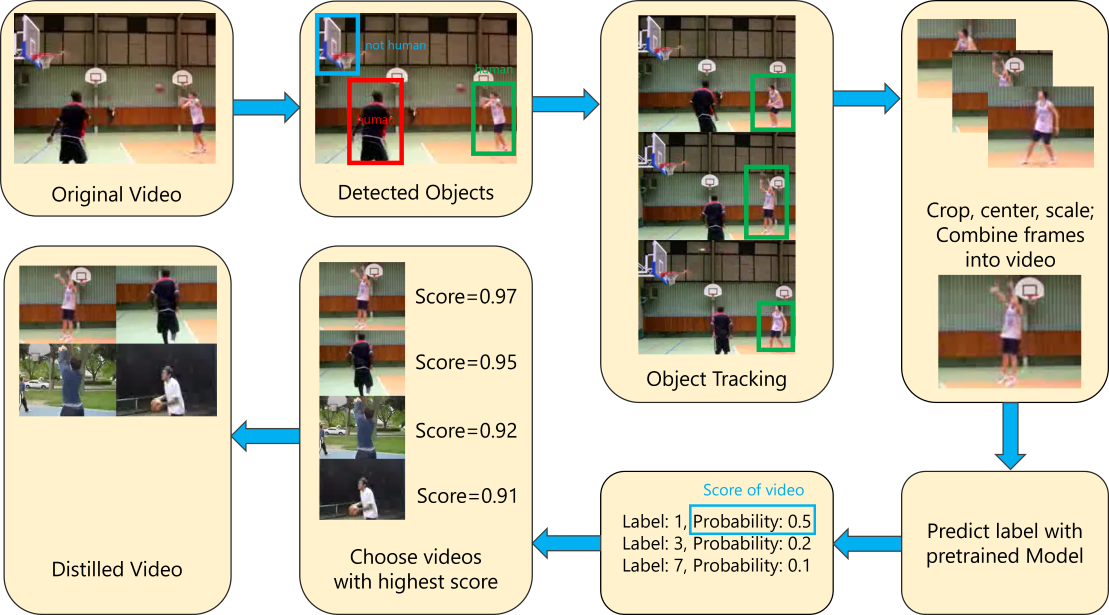
Training large neural networks on video datasets presents substantial computational challenges, especially when dealing with high-resolution and large-scale data. Inspired by recent advances in dataset distillation, we propose a novel approach to video data distillation, aiming to compress and optimize video datasets for efficient training while preserving critical characteristics such as realism, diversity, and efficiency. Our method demonstrates significant improvements in both accuracy and computational efficiency, achieving comparable performance to models trained on full datasets, but with drastically reduced computational cost. We conduct extensive empirical evaluations across various video datasets and model architectures, showing that our approach can effectively distill large video datasets into compact yet high-fidelity subsets, maintaining key properties crucial for real-world video applications.